Testing Methods
Every methodology we use to extract clean, statistically valid signals from your social content experiments.
Four Frameworks for Every Situation
Choose the right testing approach based on your timeline, budget, and the complexity of what you're testing.
A/B Split Testing
The gold standard for testing a single variable between two content variants.
- 1Define the single variable under test (e.g., hook text)
- 2Create two identical posts with only that variable changed
- 3Distribute traffic 50/50 to equal audience segments
- 4Declare winner at 95% statistical confidence
Multivariate Testing
Test multiple elements simultaneously to find the optimal combination.
- 1Map all variables to be tested in a factorial grid
- 2Generate all required variant combinations
- 3Run across evenly distributed audience pools
- 4Use interaction analysis to find the winning combo
Sequential Testing
Monitor continuously and stop as soon as significance is reached — no fixed sample size.
- 1Set a maximum sample size and significance threshold
- 2Monitor data continuously as it accumulates
- 3Apply sequential probability ratio test (SPRT)
- 4Stop early when significance boundary is crossed
Bandit Testing
Adaptive allocation — automatically shift budget toward better-performing variants in real time.
- 1Start with equal distribution across all variants
- 2Algorithm detects early performance signals
- 3Shift impressions toward better-performing variants
- 4Continue until winner is dominant and confirmed
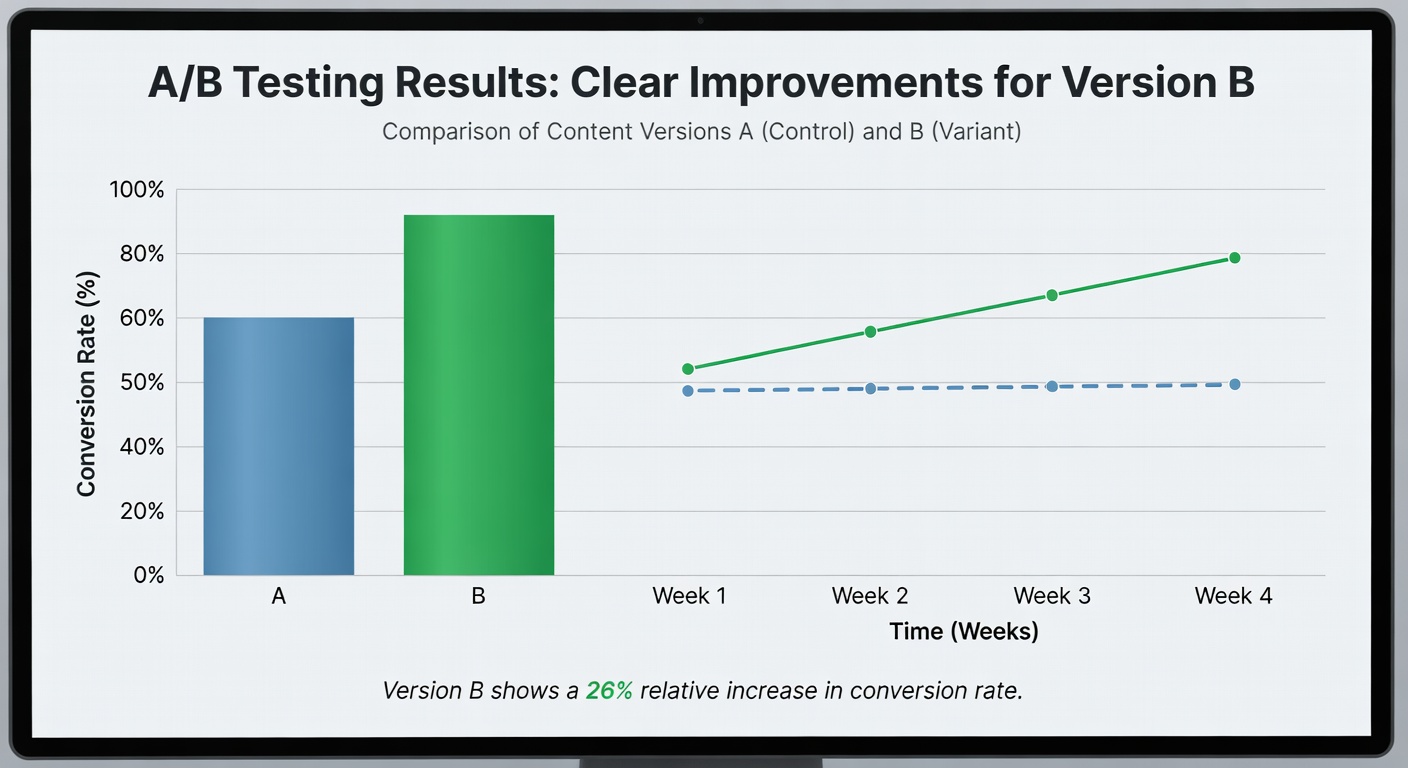
A/B Test Results That Drive Confident Scaling
Our A/B testing dashboard gives you a clear view of which variant is winning, the confidence level, and the projected impact of scaling the winner across your full distribution budget.
- Real-time confidence interval tracking
- Uplift projections with reach and revenue estimates
- Automatic loser kill to stop wasting spend
- Test history log with learnings archive
Choosing the Right Testing Approach
The right method depends on your audience size, content type, and how much time you have.
| Method | Time to Result | Best For | Speed Rating |
|---|---|---|---|
| Sequential Testing | 24–72 hours | Time-sensitive campaigns | Fastest |
| A/B Split | 3–7 days | Standard content tests | Fast |
| Bandit Testing | 5–10 days | Revenue-critical content | Moderate |
| Multivariate | 7–21 days | Full creative optimization | Slower |
| Method | Min. Budget | Budget Efficiency | Recommendation |
|---|---|---|---|
| Sequential Testing | $200 | Up to 40% savings | Best Value |
| A/B Split | $300 | Standard | Recommended |
| Bandit Testing | $500 | Maximizes revenue during test | For Revenue |
| Multivariate | $800+ | Higher upfront, deeper insight | For Scale |
| Platform | Recommended Method | Key Variable to Test | Avg. Test Duration |
|---|---|---|---|
| TikTok | A/B Split | First 3-second hook | 2–4 days |
| Instagram Reels | Sequential | Cover frame + caption | 3–5 days |
| YouTube Shorts | Multivariate | Hook + thumbnail | 7–14 days |
| A/B Split | Opening line + CTA | 5–10 days |
Multivariate Interfaces Built for Speed and Clarity
Our multivariate testing interface lets you configure complex factorial experiments without a data science degree. Define variables, set sample sizes, and launch — the platform handles the statistics.
- Drag-and-drop variant builder with live preview
- Automated interaction effect detection
- Smart recommendations for follow-up tests
- Export-ready reports for stakeholder sharing
Common Testing Questions
Answers to the most frequent questions we get about setting up and interpreting content tests.
For most content tests, you need at least 3,000–5,000 impressions per variant to achieve 95% statistical confidence. For smaller effect sizes (under 15% difference), aim for 8,000–10,000 per variant. Our platform calculates the required sample size automatically based on your expected lift and confidence threshold.
Yes, but be careful about audience overlap. Running simultaneous tests on the same audience can cause interaction effects that pollute your data. We recommend using separate audience segments for concurrent tests, or using our Isolation Mode that automatically creates non-overlapping test pools.
We recommend 95% for most content decisions. If you're making a large budget commitment (scaling spend by 5×+), use 99% confidence. For rapid iteration in early-stage testing where you're just generating directional hypotheses, 90% is acceptable — but don't make major budget shifts based on 90% confidence alone.
Peeking bias occurs when you check results too early and make decisions before reaching statistical significance. Our platform uses a sequential testing approach with built-in alpha spending functions (O'Brien-Fleming boundaries) that allow you to monitor continuously without inflating false positive rates.
Start Your First Content Test Today
Get a structured testing framework configured for your platform and content type in under 30 minutes.
Get Started Free